
Comenzamos con una advertencia: NADIE, salvo los ingenieros directamente implicados en el desarrollo del algoritmo de Google, está en disposición de explicar con exactitud cómo funciona dicho algoritmo. Es necesario entender que existen dos buenas razones para que esto sea así.
- El algoritmo es producto de la inversión y desarrollo de una empresa privada, por lo que supone un secreto empresarial de gran valor. Teniendo en cuenta que miles de millones de personas lo utilizan cada día, podemos afirmar sin ninguna duda de que es uno de los productos humano más consumidos de la historia de la humanidad, a la misma altura que la bombilla o la rueda.
- Si el algoritmo fuera público, cualquier usuario malintencionado podría manipularlo a su favor. Esto no solo iría en contra del principio que se marcó originariamente Google de dar al usuario que busca un resultado que satisfaga su búsqueda, sino que terminaría provocando que la calidad del consumo de los contenidos derivados de búsquedas en Google fuera cada vez peor, generando a la larga un internet de contenidos de baja relevancia y posiblemente inútil.
Dicho eso, puedes encontrar muchísimos artículos que tienen como objetivo arrojar luz sobre este tema, igual que el artículo que tienes delante, pero muchos de ellos caen en el ámbito de la especulación sin advertirlo al lector, dando por confirmadas ideas o hipótesis que no son más que mera opinión. En este artículo trataré en cada momento de establecer qué afirmaciones están confirmadas y cuáles no lo son, pero son fruto de la lógica.
Contenido
¿Qué es el algoritmo de búsqueda de Google?
Empecemos con una aproximación.
El algoritmo de búsqueda de Google es un conjunto de programas que interactúan entre sí en un proceso interno cuya finalidad es clasificar el contenido de internet para mostrar un listado de resultados a las búsquedas que hacen los usuarios. Para ello, el algoritmo tiene en cuenta una serie de elementos que afectan a cada sitio web y cada URL que la conforma, como pueden ser la relevancia del contenido o su calidad en función de la búsqueda que hace el usuario e, incluso, en función del propio usuario, como veremos más adelante.
Antes de entrar en detalle, es útil detenerse en las etapas que sigue Google para clasificar un contenido determinado en internet.
1ª etapa: Rastreo
Los Crawlers («arañas») de Google son programas o bots cuya finalidad es rastrear todo internet a la búsqueda del contenido de las páginas web que existen, ya sean nuevas páginas web, antiguas, contenido nuevo, actualizado, etc.
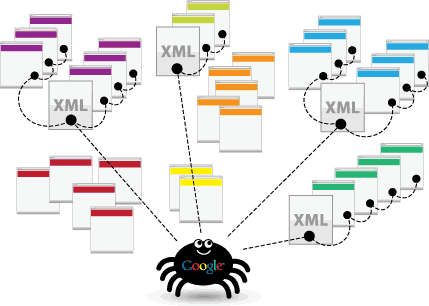 ¿Cómo funciona exactamente el crawler? Se trata de un pequeño programa que sigue los enlaces de una página a otra. Cada página en la que aterriza la «araña» se copia y es transmitida a los servidores de Google. Pero es muy importante entender que lo que la «araña» copia y transmite no es el contenido íntegro de toda la página web, ya que guardar un registro completo de cada página en todo internet sería un trabajo inabarcable (con la implementación de la computación cuántica en un futuro cercano, la cosa cambiará). Por este motivo, Google sólo registra el código de la página y, además, determina qué páginas o URLs no son útiles y las deshecha, no enviándolas o borrándolas de sus bases de datos.
¿Cómo funciona exactamente el crawler? Se trata de un pequeño programa que sigue los enlaces de una página a otra. Cada página en la que aterriza la «araña» se copia y es transmitida a los servidores de Google. Pero es muy importante entender que lo que la «araña» copia y transmite no es el contenido íntegro de toda la página web, ya que guardar un registro completo de cada página en todo internet sería un trabajo inabarcable (con la implementación de la computación cuántica en un futuro cercano, la cosa cambiará). Por este motivo, Google sólo registra el código de la página y, además, determina qué páginas o URLs no son útiles y las deshecha, no enviándolas o borrándolas de sus bases de datos.
Las arañas trabajan de una manera muy específica, saltando de enlace en enlace descubriendo nuevas páginas. Por eso, si tu contenido no está enlazado no será indexado.
¿Sabías que cuantos más enlaces externos tenga una página web o URL más fácil y probable es que Google pueda localizar esa página o URL? Esto ocurre porque Google no solo rastrea de forma estática una web, sino que al hacerlo «persigue» también aquellas otras páginas web o URLs a las que está enlazando. Esa es la forma «inteligente» que usan los crawlers para saltar y navegar por todo internet.
Cuando el crawler se encuentra un nuevo dominio, lo primero que busca es el archivo robots.txt dentro del directorio principal de dicho dominio.
Este archivo es fundamental y vale la pena tenerlo bien configurado. Cualquier mensaje que se quiera dejar en el archivo para el crawler, como qué contenido quieres que se indexe o dónde puede Google encontrar tus sitemaps, puede dejarse en esta página. Eso sí: aunque la araña debería seguir estas instrucciones, no tiene por qué hacerlo. Puede seguir otros criterios que para ella sean más relevantes o eficientes que las instrucciones del archivo robots.txt.
Si bien este paso es vital para Google y, por tanto, para la clasificación de una página web en los resultados de búsqueda, encontrar el contenido no es la parte esencial. Eso viene después.
2ª etapa: Indexación
El siguiente paso que realiza Google, una vez localizadas las URLs, es analizarlas y tratar de averiguar de qué tratan. Para ello, analiza el contenido textual, su estructura, las imágenes y otros archivos multimedia, y luego almacena esta información en una gigantesca base de datos conocida como Google Index.
Durante las dos primeras etapas (Rastreo e Indexación) es fundamental que el SEO técnico de tu página esté muy optimizado. Esto es aún más importante si la página web es de nueva creación. Elementos como los sitemaps, el archivo robots, los encabezados, las etiquetas y metaetiquetas, el enlazamiento interno, el contenido textual, etc, son cruciales para que Google determine de qué van tus URLs y cómo las deberá clasificar.
Un principio fundamental en computación es que cuando se tiene a disposición una gran cantidad de contenido, se necesita una forma rápida y eficiente de acceder a ese contenido. Google no puede tener una gran base de datos que contenga todas las páginas para ordenarlas cada vez que se introduce una consulta. Sería demasiado lento. En su lugar, el índice que crea Google acorta este proceso. Los motores de búsqueda utilizan tecnología como Hadoop para gestionar y consultar grandes cantidades de datos con gran rapidez. Buscar en el índice es mucho más rápido que buscar en toda la base de datos cada vez.
Un ejemplo fácil de entender serían las palabras comunes como «y», «el», «si». Son las llamadas «stop words«. Por lo general, no contribuyen a la interpretación del contenido por parte del motor de búsqueda (aunque hay excepciones: «Ser o no ser» se compone de stop words) por lo que se eliminan para ahorrar espacio. Puede ser una cantidad muy pequeña de espacio por página, pero cuando se trata de miles de millones de páginas se convierte en una consideración importante. Vale la pena tener en cuenta este tipo de pensamiento cuando se trata de entender a Google y las decisiones que toma. Un pequeño cambio por página puede ser muy diferente a escala.
3ª etapa: publicación y clasificación
 Cuando una página web ha superado las dos etapas anteriores, Google procederá a su publicación dentro de los resultados de búsqueda. Pero lo hará determinando cuáles de estas páginas son las más relevantes y útiles para una consulta de búsqueda en particular. Es decir: no solo publicará la página o la URL específica, sino que determinará dónde mostrarla en función de la búsqueda que haya hecho un usuario. Aquí es donde entra en juego directamente el algoritmo de búsqueda de Google.
Cuando una página web ha superado las dos etapas anteriores, Google procederá a su publicación dentro de los resultados de búsqueda. Pero lo hará determinando cuáles de estas páginas son las más relevantes y útiles para una consulta de búsqueda en particular. Es decir: no solo publicará la página o la URL específica, sino que determinará dónde mostrarla en función de la búsqueda que haya hecho un usuario. Aquí es donde entra en juego directamente el algoritmo de búsqueda de Google.
El contenido ya ha sido indexado. Así que Google ha tomado una copia del mismo y ha colocado un acceso directo a la página en el índice. De este modo, puede encontrarla y mostrarla cuando coincida con una consulta de búsqueda relevante. Cada búsqueda que realices en Google tendrá probablemente 1000 resultados, así que ahora Google tiene que decidir en qué orden va a mostrar los resultados.
Google decide la posición de una página web para una consulta determinado a través de su algoritmo de búsqueda. Un algoritmo es un término genérico que significa un proceso o conjunto de reglas que se siguen para resolver un problema. En referencia a Google, se trata del conjunto de métricas ponderadas que determinan el orden en el que se clasifican distintas páginas web según criterios específicos
¿Se puede saber realmente cómo funciona el algoritmo de búsqueda?
Como he dicho al principio, fuera del círculo íntimo de Google, nadie lo sabe con certeza. Los especialistas en marketing digital y posicionamiento SEO nos encontramos en la obligación de saber o aproximarnos a saber cómo funciona exactamente, porque eso nos permitirá saber qué debemos hacer para clasificar nuestras páginas web en las SERPs. No obstante, no todo es silencio. Google publica constantemente noticias e información relevante en su cuenta de Twitter y también tiene publicado un Libro Blanco destinado a los webmasters que da mucha información relevante al respecto.
Gracias a ello, el algoritmo de Google ya no es un misterio insondable, como era antes. En realidad, los factores y las métricas individuales que lo componen están bastante bien documentados. De esta forma, podemos saber cuáles son las principales métricas On-Page y Off-Page. La dificultad se encuentra en entender cuál es la correlación entre ellas.
Veamos un ejemplo: si buscas «recetas de pasteles de chocolate», el algoritmo ponderará las páginas en función de ese término de búsqueda.
Simplificando, podemos ver dos métricas que se influyen mutuamente.
La métrica 1 sería la URL. Las palabras clave pueden aparecer en la URL, como por ejemplo: /recetas-pastel-chocolate. Google puede ver las palabras clave «pastel de chocolate» y «recetas» en la URL, por lo que puede aplicar una ponderación en consecuencia.
Ahora pasamos a la métrica 2: que serían los backlinks de la página. Muchos de ellos pueden contener las palabras clave «pastel de chocolate» y «recetas«.
¿Qué hace Google con estas dos métricas? Podemos suponer dos posibilidades:
- Google le da menos peso a la métrica 2 ya que las palabras clave aparecen en la URL, de forma que es de esperar que aparezcan en los backlinks, sean relevantes o no.
- Por el contrario, Google podría optar por aplicar más peso a la métrica 2 si las palabras clave no aparecieran en ninguna parte de la URL.
Todos los factores que Google tiene en cuenta se afectan mutuamente. Cada uno puede valer más o menos (en la ponderación) y la relación entre ellos cambia constantemente.
Google emite cientos de actualizaciones cada año, ajustando constantemente esto. Lo más habitual es que esta relación y la ponderación cambien más que las propias métricas. Cuando esto ocurre, solemos hablar de una actualización en el Core de Google (como en su día fueron Penguin o Panda).
La respuesta oficial de Google
Desde 2019, Google ha brindado una gran cantidad de información y consejos a través de sus canales de comunicación oficiales, incluidas pautas detalladas sobre lo que se valora cuando clasifica el contenido en los resultados de búsqueda.
John Mueller, el analista sénior de tendencias para webmasters de la compañía, también actúa a menudo como un portavoz no-oficial de Google dentro de este ámbito. A través de blogs regulares, publicaciones en redes sociales y apariciones en seminarios web, conferencias y otros eventos de medios, con frecuencia intenta cerrar la brecha de conocimiento entre el propio Google y la comunidad de SEO en general. Por supuesto, no esperes que Mueller o Google divulguen ninguna información formal sobre el algoritmo en sí, pero a menudo dejarán algunas pistas bastante importantes sobre cómo mantenerse en el lado bueno.
Aquí tienes un listado de canales donde podrás estar al día:
Canal oficial de Twitter de Google SearchLiason. Tweets oficiales de @dannysullivan, compartiendo información sobre cómo funciona la búsqueda en Google.
Cómo funciona la búsqueda en Google. Una explicación del mismo Google del funcionamiento de su algoritmo.
Objetivos del algoritmo de búsqueda de Google. Aquí podemos comprender cuál es la misión de Google. Esta parte es muy importante: muchos dirán que Google nos da aquellos resultados de búsqueda que más le aportan a él como negocio. En realidad, el negocio de Google consiste en darle al usuario la mejor experiencia de búsqueda posible, y por eso Google se asegura de que los resultados que muestra sean relevantes para el usuario que busca. Solo así, se garantiza mantener la hegemonía como buscador en internet. Entender este principio ayuda mucho a la hora de construir nuestros propios contenidos y estudiar las palabras clave que queremos posicionar.
Canal de youtube de Google Webmasters. Canal oficial de YouTube de Google Search Central (anteriormente Google Webmasters), donde puedes encontrar información y herramientas que te ayudarán a comprender y mejorar tu sitio en la Búsqueda de Google.
Cuenta de Twitter de John Mueller. Otra cuenta de Twitter fundamental.
Foros oficiales de Google para Webmasters. Un contenedor vivo de información relevante y de soluciones de lo más variopintas a preguntas no menos curiosas. Un fuente inagotable de información
Factores clave de clasificación
Los factores que voy a explicar a continuación se basan principalmente en la información que Mueller y Google han ido dando en el pasado. A medida que los vaya tratando, también indicaré cómo podemos tenerlos en cuenta y aplicarlos a nuestras estrategias de SEO.
Significado e Intención de búsqueda
Todo usuario que realiza una búsqueda tiene una intención. La intención podríamos definirla como la expectativa que tiene dicho usuario frente al resultado que ofrezca Google, que se traducirá en una acción. Esta acción dependerá de si el resultado satisface o no dicha expectativa. Por ejemplo: si hago la búsqueda «comprar zapatillas online», probablemente mi intención sea la de comprar alguna zapatilla en un ecommerce. Lo lógico es que Google me muestre resultados en las SERPs que puedan proporcionarme una resolución satisfactoria a esa expectativa que tengo. Si en vez de mostrarme tiendas online de venta de zapatillas, me muestra artículos informativos sobre plantas o jardinería, ningún resultado satisfará mi intención inicial y la experiencia con el motor de búsqueda será deficiente.
Dentro del algoritmo de búsqueda de Google, comprender y aclarar el significado y la intención de la consulta de búsqueda es el primer paso clave. Los mecanismos que permiten esto son, nuevamente, un secreto, pero sabemos que funcionan a distintos niveles semánticos y estructurales, gracias a los cuales el algoritmo tiene en cuenta cosas como:
- El alcance de la consulta. ¿El usuario busca resultados en torno a un tema más amplio, como «cómo iniciarse en la jardinería», o uno específico, como «qué herramienta de jardinería se debe usar para una tarea en particular»?
- Sinónimos. Este sistema tardó cinco años en construirse y le permite a Google comprender, por ejemplo, que «cambiar una bombilla» significa lo mismo que «reemplazar una bombilla».
- Idioma. Si la consulta de búsqueda está escrita, por ejemplo, en español, ¿significa que el usuario quiere los resultados en español?
- Localidad. ¿El usuario está buscando información comercial a nivel local, como el horario de apertura de su McDonald’s más cercano, o está buscando información sobre McDonald’s en general?
- Frescura. Si el usuario está buscando, por ejemplo, el precio de las acciones de Tesla o los últimos resultados de la liga de fútbol, entonces Google puede interpretar que solo la información más actualizada será valiosa y útil para él.
Tienes que asegurarte de que tu contenido esté optimizado teniendo en cuenta la intención de búsqueda del usuario, atendiendo a todos los factores que hemos visto antes. Por ejemplo, debes asegurarte de que la intención detrás de las palabras clave que estés trabajando sean claras (esto se puede hacer utilizando herramientas de investigación de palabras clave como Semrush) y que prestes mucha atención a los marcadores locales si estás trabajando el SEO de un negocio con carácter local.
Relevancia
Cuando el usuario hace una búsqueda, el algoritmo analiza el significado y la intención de la búsqueda, y a continuación consulta el índice de Google para identificar qué páginas ofrecen la solución más relevante.
La pregunta que Google se hace es: ¿cómo de relevante es el contenido de esta web para la consulta que ha hecho el usuario? Para responder a ello, el algoritmo sigue estos pasos:
- Accede a Google Index para comprobar los datos que tiene relativos a las páginas web que podrían satisfacer a la búsqueda.
- Analiza los elementos On-Page de las páginas que tiene indexadas para comprobar cuáles y cuántos de ellos se ajustan a un resultado relevante: títulos de las páginas, textos ancla, jerarquía de contenido, etc.
- Analiza aquellos factores externos (Off-Page) que mencionan la página web, especialmente aquellos elementos de enlazamiento y el acnhor con el que enlazan.
- Determina la relevancia desde el punto de vista del dominio. Esta parte es muy importante y tiene que ver con el factor que veremos a continuación: la autoridad. Si el dominio en su conjunto se considera relevante para el término de búsqueda, esto va a aumentar la puntuación de relevancia de la página individual que se está puntuando.
Aquí es donde el SEO en la página es muy importante, ya que una de las señales más básicas de relevancia es si su página contiene las mismas palabras clave que la consulta de búsqueda (especialmente si están en sus encabezados). Más allá de esto, Google implementa “datos de interacción agregados y anónimos”, lo que significa que explora la relevancia de la página mucho más allá de las simples menciones de palabras clave. Por eso es importante establecer un tema real más allá de la palabra clave, asegurándote de que el contenido sea relevante para la consulta de búsqueda y aumentando las posibilidades de que sea leído.
Autoridad
Antiguamente Google utilizaba una métrica propia a la que llamaba PageRank (llamado así por su inventor Larry Page). Consistía en una puntuación de 1 a 10 y era la columna vertebral de cómo Google clasificaba el contenido. En realidad el PageRank no ha desaparecido, pero se ha transformado y su valor ya no es público. Entender el PageRank es parte de la clave para comprender el funcionamiento de Google, pero conviene recordar que hay cientos de factores adicionales que también pueden afectar a la clasificación, y que el PageRank es menos importante que en el pasado.
El PageRank se explica a menudo en términos de votos. Cada enlace a una página es un voto, y cuantos más votos tenga, mejor será su clasificación. Si una página con muchos votos enlaza a otra página, entonces parte de ese poder de voto también se transmite. Por lo tanto, aunque una página sólo tenga un enlace, si ese enlace procede de una página que tiene muchos votos, es posible que se clasifique bien y que las páginas a las que enlaza también se beneficien de ello. El valor que se transmite de una página a otra a través de los enlaces se conoce como link juice.
La relevancia también es importante en el contexto de la autoridad. Un enlace con un texto de anclaje relevante puede tener más peso que un enlace que no provenga de un sitio relevante y que no tenga un texto de anclaje relevante, y que Google probablemente no lo tenga en cuenta en el contexto de ese resultado de búsqueda.
Calidad
En los últimos años Mueller ha hecho muchas referencias al concepto de calidad como un factor importante de posicionamiento. De hecho, desde 2019 Google ha ido comunicando periódicamente una serie de pautas detalladas para que los SEO y los especialistas en Content Marketing tengan una idea clara de cuál es el camino a seguir.
Dentro de estas pautas, Google proporciona una serie de preguntas que pueden evaluar la calidad de su contenido, muchas de las cuales se centran en los conceptos de Experiencia, Autoridad y Confiabilidad. Estos son los tres pilares de evaluación que conforman el proceso EAT (Expertise, Authoritativeness, and Trustworthiness) de la compañía.
¿Qué es EAT?
EAT es una de las partes más importantes del algoritmo de Google. Pero no podemos tomarlo como el juez definitivo de la evaluación de la calidad del contenido. Ten presente que ahora Google emplea evaluadores de calidad de búsqueda humanos para verificar los resultados que arroja en las SERPS el algoritmo. Sobre todo cuando se trata de búsquedas sensibles, como veremos en el siguiente apartado.
Por ejemplo, una vez que se ha subido un contenido y Google lo ha indexado, el algoritmo realizará una evaluación en función de su calidad (por supuesto, no sabemos cómo se realiza exactamente esa evaluación). Después, un calificador de calidad de búsqueda humano podrá revisar el contenido indexado y tomará una decisión sobre si contiene un EAT «fuerte» antes de clasificarlo.
Estas decisiones se toman en función de las Directrices del evaluador de calidad de búsqueda (SQEG), un documento PDF detallado que está disponible públicamente y que puedes CONSULTARLO AQUÍ. Por lo tanto, puedes ver por ti mismo cómo de probable es que se evalúe la calidad del contenido de tu página web. El PDF SQEG de Google brinda instrucciones claras y detalladas sobre cómo sus evaluadores definen la calidad.
Tu dinero o tu vida (YMYL)
Dentro del SQEG, también vale la pena prestar especial atención a lo que Google define como contenido YMYL (Your Money or Your Life), que toca en gran medida los aspectos de «autoridad» y «confiabilidad» de las pautas EAT.
El contenido de YMYL es cualquier información que publique y que pueda afectar el bienestar, la salud, la seguridad o la estabilidad financiera de un lector. En tales casos, es probable que Google ni siquiera considere clasificar tu contenido a menos que esté escrito por un experto relevante.
Por ejemplo, si produces una publicación de blog que defiende un tipo particular de dieta, entonces deberá ser escrita por un profesional relevante, como un dietista. Un artículo sobre los pros y los contras de un plan de pensiones en particular debe ser escrito por un profesional financiero certificado, y así sucesivamente.
El SQEG brinda pautas detalladas sobre lo que se clasifica como contenido YMYL, y son un factor de clasificación importante dentro del algoritmo de búsqueda de Google, así que asegúrate de seguir las pautas al respecto. Google también es explícitamente claro sobre cómo juzga y clasifica el contenido de YMYL.
Confianza
Para evaluar la confianza de una página web, Google cuenta con un algoritmo anti-spam, centrado en dificultar la manipulación artificial de los resultados de búsqueda. Hay que entender que Google tiene una relación de amor-odio con el SEO y el mecanismo de confianza forma parte de ella. Por un lado, gran parte del SEO consiste en crear contenido y optimizar la experiencia de usuario. Pero por otro lado, el SEO también trata de manipular artificialmente lo que Google ha determinado como el orden natural de los resultados.
Las métricas de confianza son muy difíciles de manipular y dan a Google una base sólida para valorar las demás métricas. Cosas como la antigüedad del contenido o el dominio son métricas de confianza. Si tienes muchos enlaces procedentes de «malos barrios», estos enlaces no sólo no tendrán ningún valor, sino que también harán que Google se lo piense dos veces a la hora de clasificar tu sitio para esa búsqueda de «receta de tarta de chocolate». De la misma manera, si la página o el dominio enlaza con malos vecindarios, va a dañar las métricas de confianza.
¿Sabías que…?
… Google es un registrador de dominios, lo que significa que puede ver todos los datos whois de los diferentes dominios. Esto les permite incorporar información relevante que afecta a las métricas de calidad, como la frecuencia con la que un dominio ha cambiado de manos o el tiempo que falta para que el registro expire,, entre otras. Estas son mucho más difíciles de manipular.
Experiencia de usuario
Según Google, su algoritmo busca promover páginas con un buen UIX (experiencia y diseño para el usuario) sobre aquellas que son menos «usables», particularmente donde identifica «persistent user pain points» (puntos débiles persistentes para el usuario).
En realidad, esto significa que el algoritmo de búsqueda da preferencia a los sitios que:
- Carguen y aparezcan correctamente en diferentes navegadores web (es decir, Chrome, Firefox, etc.)
- Son compatibles con diferentes tipos y tamaños de dispositivos (es decir, ordenadores de escritorio, portátiles, tabletas y teléfonos móviles)
- Presenta tiempos de carga rápidos, incluso para usuarios con velocidades de Internet lentas
Google suele advertir a los webmasters sobre cualquier actualización importante que pueda estar a punto de ocurrir, y también proporciona una serie de herramientas para ayudarlos a medir y mejorar la usabilidad y el rendimiento de su sitio.
Google ha confirmado que sus métricas de UX, conocidas como Core Web Vitals, son un factor de clasificación. Sin embargo, Mueller afirmó en 2021 que si bien los Core Web Vitals son muy importantes, no reemplazan la relevancia.
Ten en cuenta:
Google quiere que el contenido que muestra en sus resultados de búsqueda sea atractivo tanto para los humanos como para los robots de los motores de búsqueda. Existe un conjunto de métricas que se dedican exclusivamente a estos factores. Tener un gran contenido pero luego, por ejemplo, cubrirlo de anuncios no va a suponer una gran experiencia para el usuario. Por eso, Google rebajará la importancia de una página en la que la publicidad sea demasiado prominente.
La velocidad de la página es otro factor importante; las páginas que se cargan con demasiada lentitud resultan molestas para los buscadores, lo que hace que la gente vuelva a hacer clic en los resultados de búsqueda y elija otra página. Google quiere que los usuarios sigan utilizando Google, por lo que les interesa que los resultados que muestran se carguen rápidamente. La velocidad de la página se mide a partir del HTML, pero también puede utilizar los datos de los usuarios de Chrome.
Contexto
Este factor de clasificación está estrechamente relacionado con la relevancia, pero también tiene en cuenta el contexto personal y la configuración del buscador. Por ejemplo, si alguien en los EE. UU. busca «resultados de fútbol de hoy«, es probable que vea los resultados de fútbol americano (es decir, NFL) de ese día. Sin embargo, si alguien en el España busca lo mismo, es probable que vea los resultados de la Liga de fútbol española, que es otro deporte distinto.
Otro factor contextual es el dispositivo desde el que realizas la búsqueda. Si buscas en un teléfono móvil, se mostrará un conjunto de resultados diferente al de un ordenador de sobremesa. Los resultados reales devueltos por el indexador serán diferentes. Sin embargo, no es sólo el tipo de dispositivo el que afecta a los resultados que se ven, sino que Google puede optar por mostrar los resultados en un formato totalmente diferente en función de los términos de búsqueda que se utilicen.
El algoritmo también puede identificar patrones y preferencias en función de búsquedas anteriores y proporcionar resultados en consecuencia. Por ejemplo, si alguien busca «Valencia«, pero también busca regularmente «Valencia C.F.«, el algoritmo puede interpretar que el usuario quiere información sobre el equipo de fútbol en lugar de la ciudad. En este grado de personalización, lo que hayas buscado anteriormente influirá en los resultados que Google devuelva. Hay un grado de aprendizaje automático en funcionamiento aquí. Así, cuando alguien busca un tipo de resultado de forma consistente, Google asumirá que las futuras búsquedas similares serán de la misma naturaleza. Esto es especialmente importante en el caso de las búsquedas ambiguas, en las que una palabra tiene varios significados.
Además, los resultados que muestra Google pueden variar en formato dependiendo de estos factores de personalización. Las búsquedas localizadas se ponderan de forma diferente y se muestran en un formato de página de resultados distinto al de, por ejemplo, las búsquedas de productos. También hay búsquedas de medios mixtos en las que Google puede mostrar resultados que incluyan vídeos e imágenes. Algunas búsquedas tienen páginas de resultados dedicadas a un conjunto muy limitado de términos. Estas suelen estar relacionadas con acontecimientos actuales, como partidos deportivos o elecciones.
Finalmente, el algoritmo también puede tener en cuenta las preferencias del buscador, especialmente si navega por la web mientras está conectado a su cuenta de Google. Por ejemplo, si el algoritmo sabe que el usuario está interesado en la música, cuando haga la búsqueda por el término «eventos cerca de mí«, podría dar prioridad a los resultados que muestren un listado de conciertos de música.
Todos estos son factores que dependen del buscador, por lo que es difícil implementar cualquier táctica que pueda mejorar el rendimiento de tu sitio web en esta etapa del algoritmo.
Actualizaciones de algoritmos
El algoritmo de búsqueda de Google es de naturaleza dinámica y siempre se modifica para garantizar que sea lo más útil posible. En ciertos puntos, se somete a actualizaciones principales más importantes que pueden afectar significativamente las clasificaciones existentes, lo que hace que algunos sitios mejoren sus clasificaciones y otros pierdan las suyas. Este tipo de actualizaciones son las «más temidas» y se conocen como «Core Update«.
Como resultado, puede ser difícil tratar de averiguar qué es exactamente lo que deberías estar haciendo como SEO en un momento determinado. No hay un calendario establecido para estas actualizaciones y, para complicar las cosas, Google no siempre confirma si se ha realizado o no una actualización.
Sin embargo, hay dos canales bastante interesantes que puedes consultar periódicamente para estar al tanto de las nuevas actualizaciones de Google.
Dos canales de información para estar al día:
Semrush Sensor. Para ver y comprender la volatilidad del posicionamiento por categorías y nichos de mercado. Muy útil para identificar si es probable que se apliquen cambios significativos en tu página web.
Actualizaciones (actualizadas) del algoritmo de Google. El mejor blog para estar al día en las actualizaciones que Google va introduciendo en su algoritmo (en inglés). Es muy útil, porque aunque Google no comunica directamente los cambios que realiza, los artículos de este blog se escribe a partir de distintas fuentes de discusión entre webmasters y técnicos SEO que permiten establecer las causas de los cambios de posición en determinados momentos o nichos.
Conclusiones
Como puedes ver, es difícil tener una idea exacta de a qué da prioridad exactamente el algoritmo de búsqueda de Google. Además, un error que comenten muchos técnicos es afrontar este asunto como si estudiara una ciencia natural cuyas leyes son estáticas. Google modifica sobre la marcha cuestiones relevantes para el posicionamiento. No se pueden entender sus reglas de forma cerrada y absoluta.
Sin embargo, la buena noticia es que Google es bastante comunicativo con su orientación y consejos generales. Independientemente de los cambios y actualizaciones principales, siempre buscará recompensar el contenido que es:
- De alta calidad, especialmente si se adhiere a los principios establecidos en las directrices EAT
- Relevante en términos de contenido y tema para la palabra clave a la que se dirige
- Escrito con el significado y la intención de la consulta de búsqueda en mente
- Optimizado para ofrecer una experiencia de usuario perfecta en múltiples dispositivos y plataforma.
Para conseguir buenos resultados, sigue los criterios anteriores a rajatabla, ya que no cambiarán en mucho tiempo, y para ello echa mano de herramientas que te faciliten el trabajo.